How architecture evolved from layered to Clean Architecture?
Let’s imagine an application that has no additional layers and consists of a project in which we keep all the code. For an example of code in C#:
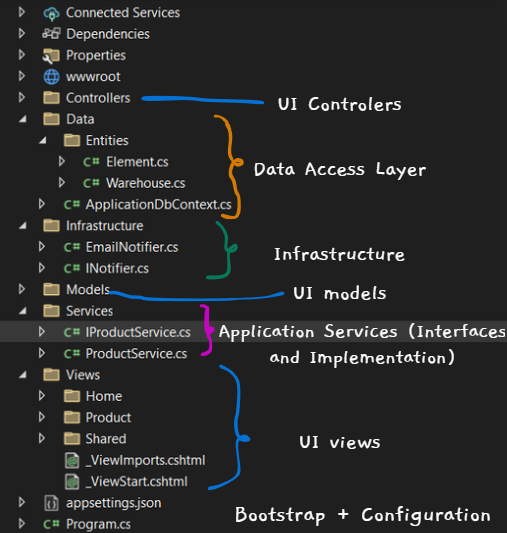
Separation of concerns is achieved through the use of folders. Files related to database access should be kept in the Data folder, and files related to views should be kept in Views.
This approach frequently leads to spaghetti code because it is easier to add dependencies from files that should not be related to each other.
Remember that good architecture allows new people to introduce changes intuitively, making the application easier to maintain. Unfortunately, this approach does not work in this way.
What can we improve? There are different ways to do his. For now, let’s focus on layers.
Evolution 1: What are layers?
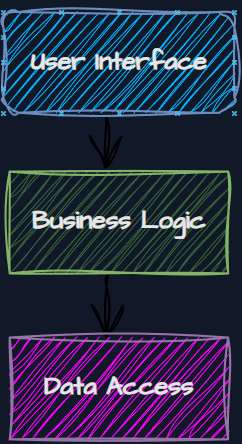
Layers are the division of the system into separate, hierarchical levels that are intended to separate various aspects of the application’s functionality. For example, the Data Access layer will be responsible for accessing the database, and we will do it only in this layer. Another higher-level layer may have a dependency on it.
In this approach, a layer can only call the layer directly beneath it!
Clear identity of each layer – It is important to have the names of layers, what they’re for, and which entities will be in them as early as possible in the architecture design process.
What do we gain?
- Separation of concerns principle – one way to manage complexity is to break up the application according to its responsibilities.
Let’s say we want to change the database to another one. In theory, we only need to touch one layer. - Scalability – Enhancements can be made in specific layers without affecting the entire system. Let it grow and adapt to the application, depending on the requirements. For example, we can add database read replicas.
- Reusability – You can reuse components within a layer across different parts of an application or even in different projects.
- Testability – You can test each layer on its own, or you can use mock objects or stubs to show how the layers work together.
What are cons?:
- There might be a negative impact on the performance – instead of calling directly, we are passing through layers.
- Maintenance – Reason the same as above.
- No dependency inversion – In a layered architecture, dependencies are direct, and conceptual changes propagate from low-level infrastructure layers to essential higher layers. (We will fix it).
What is the Dependency inversion principle? Wikipedia says:
- High-level modules should not import anything from low-level modules. Both should depend on abstractions (e.g., interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
Ideally, the upper layers should not be directly related to the lower layers. Both should interoperate through well-defined interfaces or abstract classes. This makes it easier to replace and modify individual system components without affecting other layers, increasing flexibility, and making testing easier.
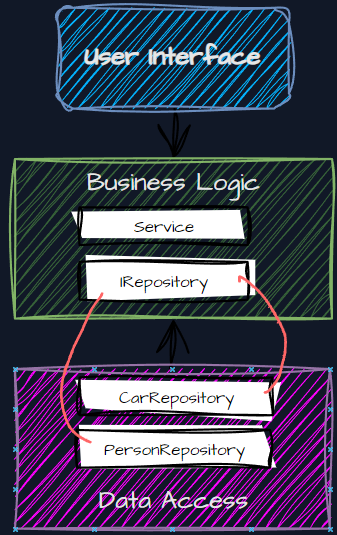
In the Layered Architecture approach, IRepository is located in the ‘Data Access Layer’ and that makes us break the rule.
Why is this such a big problem? If we try to design a system in this architecture, it is difficult for us not to start with the database, so we do not think about the domain, but start from the other side, which makes it a more data-driven system.
Evolution 2: Hexagonal architecture or “Ports and Adapters” (2005 Alistair Cockburn)
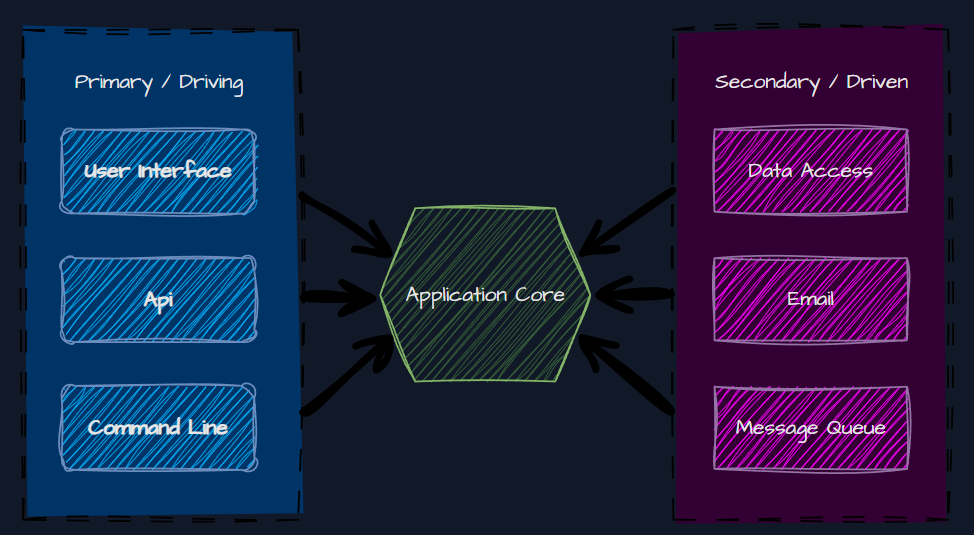
This way we have a business layer in the middle and it becomes our core application.
The Dependency Inversion Principle is a key aspect of hexagonal architecture. It separates concerns by ensuring dependencies point towards the application core.
What are ports and adapters?
Dependencies are achieved by defining ports within the application core, which represent points of interaction with external elements. Adapters handle communication between the application and the outside world.
What does it mean?
Interfaces are kept in the application core – implementation is in the correct driving or driven layer. The adapters form the boundary of the application, allowing the application to be technology-agnostic.
Where do We need to focus?
In the application core, we have domain and business logic. This architectural style separates business logic from external influences. This helps us focus on the domain, improve readability and testability, and align with Domain-Driven Design.
What are Props of Hexagonal Architecture?
- Flexibility – easy change or replace external systems without affecting the core business logic.
- Technology agnosticism – decisions regarding databases, web framework, or other technologies can be deferred because there is no impact on core application.
- Focus on the Business Domain – It is in the center 🙂
- Scalability – you can scale ports easily because they’re separated. For example, it is easier to add read replicas to the database.
- Easier Testing – Domain and each adapter can be tested separately.
What are cons of Hexagonal Architecture?
Evolution 3: Onion architecture (2008 Jeffrey Palermo)
As the Jeffrey Palermo, creator said:
The big difference is that any outer layer can directly call any inner layer. With traditionally layered architecture, a layer can only call the layer directly beneath it. This is one of the key points that makes Onion Architecture different from traditional layered architecture. Infrastructure is pushed out to the edges where no business logic code couples to it. The code that interacts with the database will implement interfaces in the application core.
So internal layers can have dependencies on external layers.
As the DDD approach has already been used and is well known, this architecture breaks down the Application Core into a more business-like approach, closer to Domain-Driven Design.
The Domain Model Layer usually focuses on the domain, and this is where the state and behaviour of domain models will be. The next layer is Domain Service, which encapsulates business logic that does not fit specific models and can work with many domain objects.
The final new layer is Application Services, which is responsible for domain operations, managing transactions and directing the flow of data in the application.
There is also a place in the diagram for integration tests, which is also very important.
The final form of onion architecture looks like this: https://jeffreypalermo.com/2008/07/the-onion-architecture-part-1/
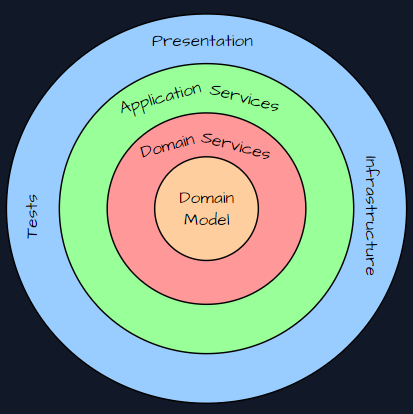
How can we read the main assumptions of Onion architecture: (Main assumptions)
– Inner layers define interfaces. Outer layers implement interfaces
– Direction of coupling is toward the center
– All application core code can be compiled and run separate from infrastructure
– The application is built around an independent object model
What we gain?
– Enhanced Focus on Domain Logic
– Improved Dependecny Management
– Simplified Testing
– Enhanced Adaptability to Changes
Evolution 4: Clean Architecture (2012 Bob C. Martin)
Onion architecture and Clean architecture are very similar, the main difference is the terminology and approach to layers.
Clean architecture uses different terminologies such as Entities, Use Cases. It provides a clearer understanding of boundaries and responsibilities.
A book describing Clean Architecture was created, which popularized this architecture, but from the point of view of evolution, the names of the layers have changed, which indicate a greater focus on the domain.
Concepts such as Controller and Gateway have also been added, but this is not part of the evolution of the architecture.
Entities -> Rich Domain Models
Use Cases -> CQRS / Business Rules
Presentation -> Interface adapters (MVC, Gateway, etc…)
Infrastructure -> Infrastructure (database, queues, etc…)
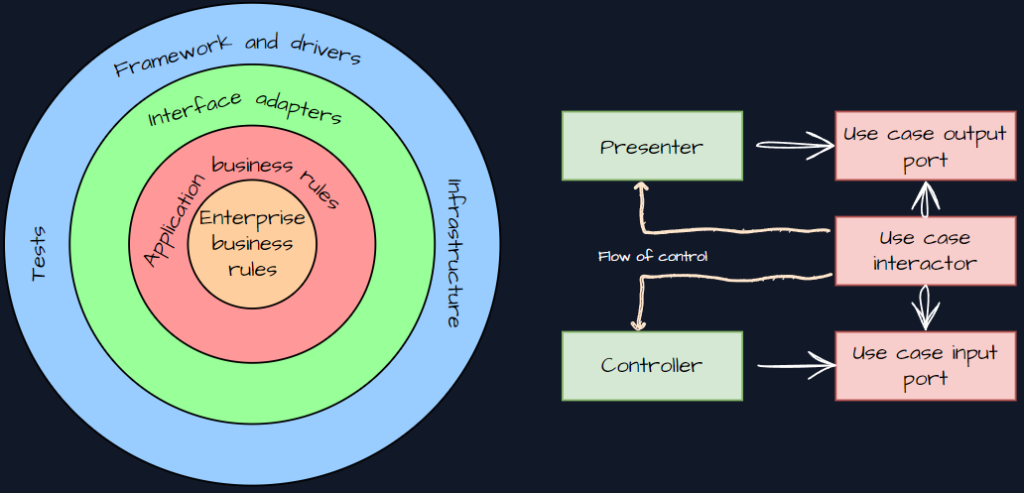
A good example of clean architecture can found on GitHub: Clean Architecture Github
This is the architecture I am most familiar with and the most frequently chosen one because, in organizations, we often solve business-related problems, so the DDD approach is very useful. Additionally, this type of architecture has been highly popularized, so it is easier to find people who will be comfortable with it.
I think I could also write about vertical slices because it allows us to improve our application with the so-called Cohesion, but I’ll leave that for a separate post.
Which caused the evolution of architecture?
- Centralized business rules – Many organizations need to solve their business problems, from which they make money. Therefore, it is worth focusing on making this part as good as possible. This should cause high cohesion in the system because We are focusing on solving business problems. Of course, there are systems aimed at more non-functional operations, but that is not what this article is about.
- Loose Coupling – One of the real things is to make sure our code isn’t spaghetti that’s hard to maintain. To avoid this, it is worth separating components in such a way that introducing changes does not force changes in places that are not related. This is achieved by dividing into layers and wisely created domain classes.
- Separation of concerns – We can archive this with well-selected layers and relations between them, e.g., those from Clean Architecture. This will allow us to focus on what is most important, for example, a domain that should not have any dependencies. However, whether we implement a mobile or web application is ultimately a detail that may change someday.
- Dependency Inversion Principle & Technology Agnosticism – High-level modules should not depend on low-level modules. Both should depend on abstraction.. For example, MsSQL to Postgres, a decision should not be made directly from a concrete implementation but rather from the system.
- Scalability – Nowadays, scalability is very important and it is important that the choice of architecture allows it.
- Modularity – It is important that the system to have posibility to be divided into distinct, self-contained components that can be developed, tested, and maintained independently.
- Easier Testing – Tests allow us to maintain the quality of the software, thanks to which the business rules from which our company makes money will not be violated if we have well-written tests.
Bibliography:
– https://learn.microsoft.com/en-us/dotnet/architecture/modern-web-apps-azure/common-web-application-architectures
– https://jeffreypalermo.com/2008/07/the-onion-architecture-part-1/
– https://dev.to/yokwejuste/dissecting-layered-architecture-2ppb
– https://learn.microsoft.com/en-us/dotnet/architecture/modern-web-apps-azure/common-web-application-architectures
– https://www.baeldung.com/cs/layered-architecture
– https://herbertograca.com/2017/08/03/layered-architecture/
– https://learn.microsoft.com/en-us/azure/architecture/guide/architecture-styles/n-tier
– https://www.techtarget.com/searchapparchitecture/tip/The-pros-and-cons-of-a-layered-architecture-pattern
– https://en.wikipedia.org/wiki/Dependency_inversion_principle
– https://betterprogramming.pub/inverting-dependencies-a-step-towards-hexagonal-architecture-ee74e11877dd
– https://thecodest.co/blog/t-strong-he-power-of-hexagonal-architecture/
– https://www.c-sharpcorner.com/blogs/onion-architecture-and-clean-architecture